
Based on my weeks of code (and operating instance) study on lemmy_server, I strongly suspect that peer servers upgrading to 0.18 is causing a swarm of federation activity that lemmy.ml is getting as peers go down and back up.
Beehaw is suppressing the news about a Lemmy outage, when their /c/Technology community is about rumors in the sidebar!
removed by mod:
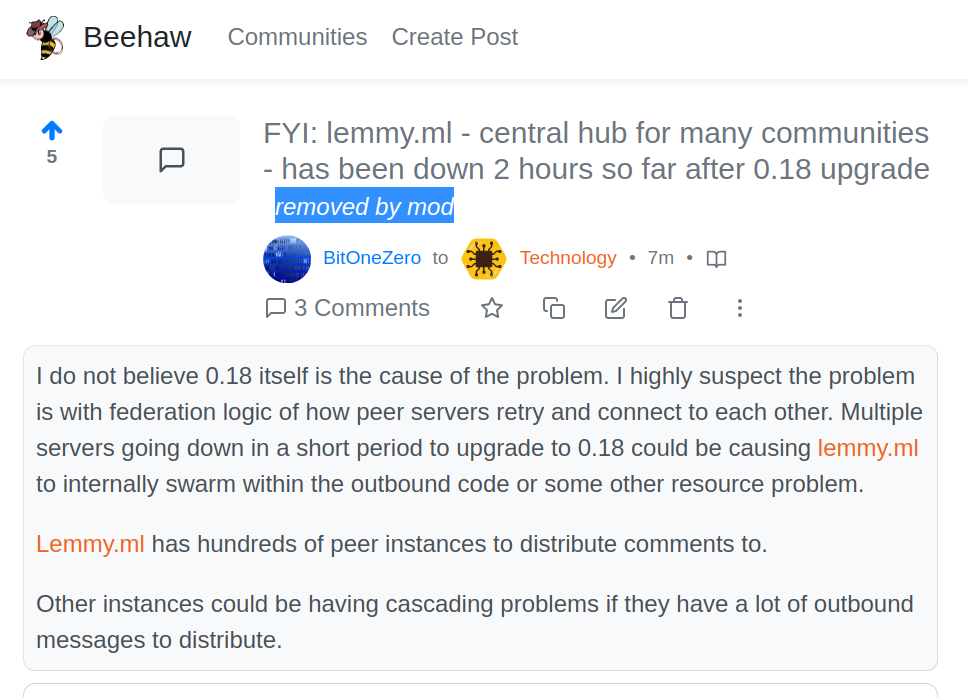
The admin of Beehaw told me to post it on Lemmy.ml despite the message being that the server was down.
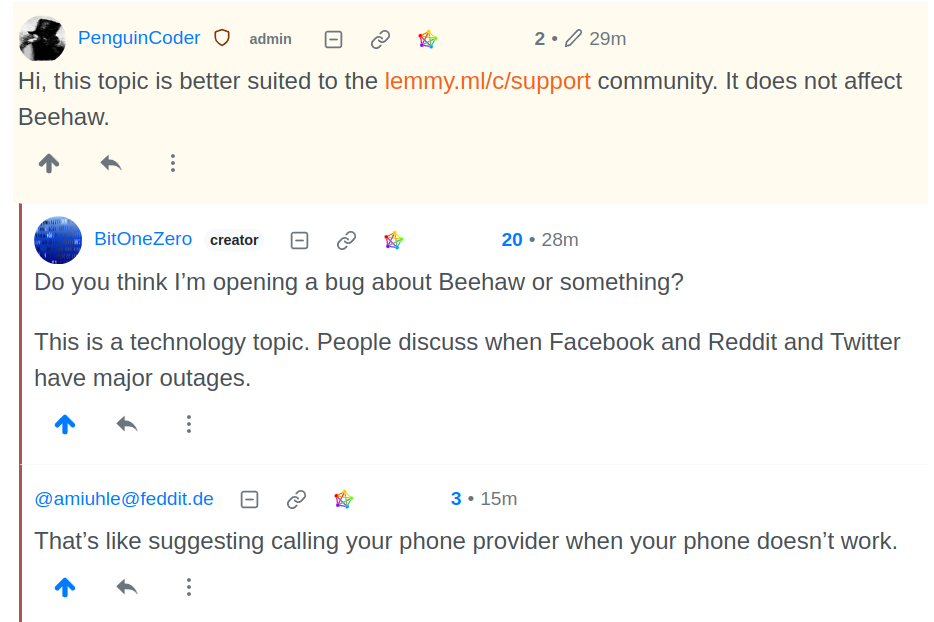
I quickly found out beehaw was not a good instance for me. This is some great reaffirmation that switching instances was the right call.
I think this is the nice part of lemmy though, many instances exist (or can create your own), and there are plenty with level headed communities/mods/admins, it just takes a bit to find what you’re looking for.
Honestly am preferring defederation from beehaw. Missing some good links (for now), sure, but those echo chamber comment sections, no thanks.
oooooh, probably all those messages that never went through are starting to slog through the system, and a million people worth of backlog are getting slogged through.
Lemmy 0.18 (and earlier) has no ability to save the federation queue, when the server stops it forgets what it had in retry to send. I suspect the problem is more the other servers going down causing lemmy.ml to keep crashing on outbound content it is sending. There are hundreds of small servers out there subscribed to lemmy.ml’s communities.
Seems like a rather bad design, if a long queue is neither saved nor sufficiently isolated to not disturb the actual usage.
They say it was a DDOS attack:

