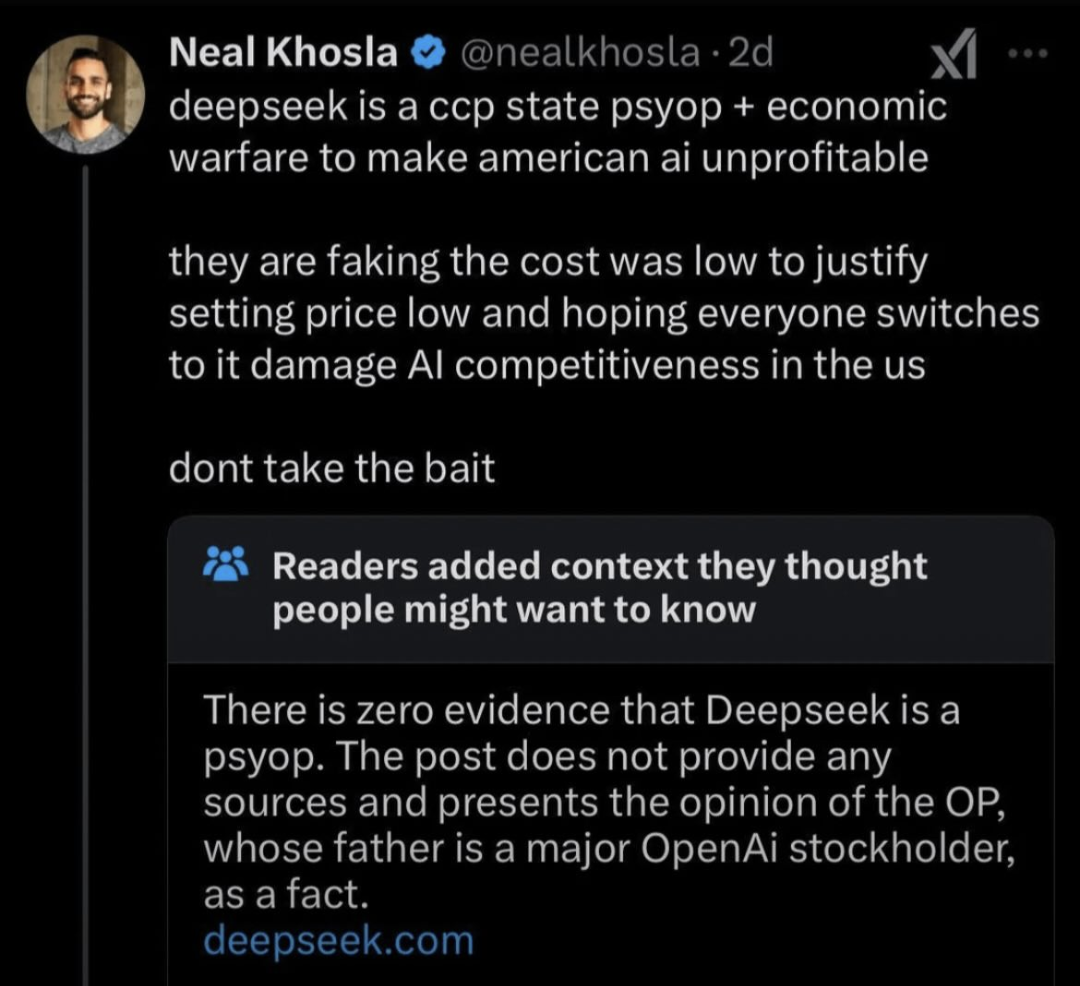
If you take into account the optimizations described in the paper, then the cost they announce is in line with the rest of the world’s research into sparse models.
Of course, the training cost is not the whole picture, which the DS paper readily acknowledges. Before arriving at 1 successful model you have to train and throw away n unsuccessful attempts. Of course that’s also true of any other LLM provider, the training cost is used to compare technical trade-offs that alter training efficiency, not business models.
{kind=link}
If you take into account the optimizations described in the paper, then the cost they announce is in line with the rest of the world’s research into sparse models.
Of course, the training cost is not the whole picture, which the DS paper readily acknowledges. Before arriving at 1 successful model you have to train and throw away n unsuccessful attempts. Of course that’s also true of any other LLM provider, the training cost is used to compare technical trade-offs that alter training efficiency, not business models.